


其实我想说求解大规模NP-hard问题一直是灌水重灾区。比如现在这帮强化学习做各种组合优化问题,可能只不过是二三十年前到现在那些元启发式算法和进化算法用来做各种组合优化问题的翻版(虽然现在已经有把RL和这些东西结合的了...以毒攻毒么)。
当然我说灌水重灾区不代表没有好文章(狗头保命),只是好文章的比例相对水文章的比例比较低一点。题主的“几十篇+,但方法就这么几种”也是这个意思(甩锅)。包括现在拿RL做组合优化问题的,如果能提出一个新的网络结构,一个新的searching机制,又有好的效果,那么发个顶会还是有希望的。像人家CV/NLP,说不定过几年就会有一个新领域:RL4CoP(RL for combinatoric optimization)。
授人以鱼不如授人以渔。我这里简单讲讲为什么强化学习从方法上确实是有希望通用性地解决组合优化问题的。
这是因为任何组合优化问题都可以转化为一个多阶段的决策问题,即动态规划问题。
我们考虑一个一般的组合优化问题:
其中 是一个有限的可行域,
是目标函数。假设每个解
有
个单元(比如
个城市旅行商问题的解,就是一个
的排列),即
。
我们来把这个优化问题写成有 个阶段动态规划的形式。我们第
个阶段的决策变量为所有可行(feasible)的
。假设初始状态为
,那么
的可行域
就可以写成
类似地,给定 ,我们下阶段的决策
需要满足
在如下可行域里:
最后一个阶段,我们到达一个终止状态,并且产生终止惩罚 。注意其余阶段我们都不产生惩罚(或收益)。
这样我们就得到了动态规划的递推式:
(定义 )
思考题:把上述递推式代入旅行商问题,会是什么样子的?
好了,跟我一起喊,动态规划牛b!自然,天下没有免费的午餐,我们很快就会发现,一般来说这个动态规划随着阶段增加会遭受维数灾难,即可能的状态数量指数级增长(思考题:为什么?)。
但是,我们却可以考虑去近似求解这个动态规划问题。一类经典的启发式算法叫做Rollout算法[1],这是一种图搜索算法,利用了任何一个有限状态动态规划问题同时可以看成一个最短路径问题(思考题:为什么?),相当于可以看成对于一个大规模最短路问题的近似算法(注意:最短路问题作为一个特殊的组合优化问题,不仅多项式时间可解,而且精确求解的时间都是接近线性的;贪心就可以)。这个算法可以看成是值函数(value function)空间上的近似算法,那么自然,如果你用上神经网络去近似,就进入所谓的深度强化学习领域:DQN和它的小伙伴们。然而实际上,这种思想也早就不新鲜,比如20多年前两位希腊学者早就此方法写过一本书,Neuro-dynamic programming[2]。
当然,随着近些年人类算力的大幅增强,和策略空间(policy space)算法的崛起,(深度)强化学习也可以用来在策略空间去求解组合优化问题。这里比如对很多特殊的组合优化问题,如果规模很大,我们一方面不需要找到那个精确最优解,另一方面我们对某些其启发式算法有比较好的理解,那么我们考虑把这些启发式算法结合起来,在策略空间里用强化学习的方法去找到一个比较好的解。对于复杂的组合优化问题,比如长久以来人工智能无能为力的下围棋(带有双人博弈),则往往需要结合值函数和策略函数上的近似算法,像当年的AlphaGo(https://www.zhihu.com/question/41176911)。
最后总结,我认为这自然是个很有前景的方向(狗头保命*2),随着现在计算机暴算能力大幅增加,大家都在努力地设计新网络、新策略、新training算法,只要能够在某具体问题上达到一个前人达不到的performance,那么自然就是很好了。除了传统的TSP、VRP、背包等经典组合优化问题,和游戏AI相关的问题往往具有更复杂的组合优化问题(信息不完全、博弈、随机性等),强化学习算法或许能给出更有价值的解(妈妈我以后打游戏再也不抱怨AI蠢了)。
什么你想做理论?那么就先看看概率论、马尔可夫过程、离散数学、凸分析、高等代数自己学的如何...
周围越来越多人开始搞强化学习了,可以说强化学习是学术界的一个趋势吧。做研究其实就是需要盲目跟风,想发好文章最容易的方法就是紧跟风口。极少有人能像Hinton那样逆大趋势而行 坐得住冷板凳的。所以这就挺好理解的为啥这方面Paper越来越多了,而且以后还会更多(哈哈,恳求各位轻点喷我)。不夸张的说今天的强化学习就是二十年前的元启发式(进化计算),各位想灌水的童鞋现在赶紧加入还来得及(小灌怡情 也没啥不好的啦)。
授人以鱼不如授人以渔, @覃含章 从比较general的角度 讲了强化学习求解组合优化的优势。那我这边作为一个补充,从一个最经典的组合优化问题TSP(旅行商问题)为例来说明 动态规划的优势所在。
设TSP问题需要经过 个城市,想要采用动态规划求解TSP问题就需要定义出state,control,system dynamic,如下所示:
state: 我们当前在城市
,已经访问过的城市集合
。
这里需要注意状态变量的定义有两部分,一部分是当前所在城市,一部分是已经访问过的城市集合(注意这里是集合不是一个序列,集合是不包含顺序信息的)
control: 下一个要去的城市是哪个
system dynamics: 。
stage cost: 从城市
到城市
的距离
Value function: 当前在城市
并且经过集合
中所有城市有且仅有一次的最小距离
完成了上面这些定义之后,接下来就是直接套用动态规划递推公式,设 为出发城市:
(1)
(2)
看到这里也就是用动态规划解了一下TSP问题了,那么动态规划强大之处在哪里呢?
我们需要对动态规划的计算复杂度进行一些分析,动态规划计算复杂度和两部分有关系一个是stage的数量,一个是状态的数量。stage的数量易知为 个,状态
由两部分构成,一部分是当前城市最多有
个取法,一部分是集合
实际上是城市集合的一个幂集,每个城市都可以选择在或者不在集合
里,因此集合
大小为
。
那么我们把以上三部分合并起来就得到算法复杂度为 ,也就是说我要最多计算式(2)
就能得到最优解了。那我们又知道如果采用暴力穷举法的话对于TSP问题我们要进行
次计算。
由此得出结论:1 动态规划求解TSP问题的复杂度依然是指数级别 ,动态规划不可能让NP=P;2 动态规划比暴力穷举法的效率要高的多,因为当
比较大的时候
。
到这里我们知道了要想用动态规划完全精确求解组合优化问题 虽然比暴力穷举法计算复杂度低很多,但依然要面临维数灾难的问题。强化学习/近似动态规划就是针对传统动态规划的不足而来的。通过一些近似的方法来降低计算量,解决传统动态规划的问题。那么近似的思路有哪些?如下图所示就是动态规划的递推公式:
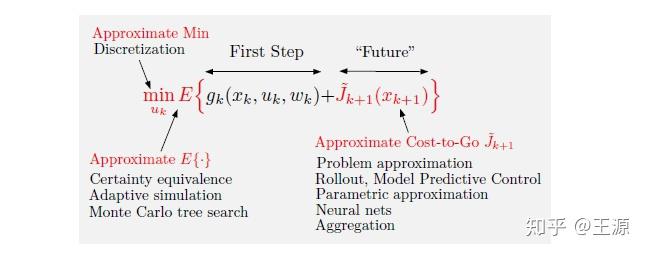
上图中红字标出了三种近似的思想:
1是Approximate Min:简单来说就是 我们在求解极小化问题的时候可以不用那么较真,能求到一个差不多的近似最优解就可以了。
2是Approximate 期望:这个也比较好理解了,很多时候我们并不知道随机变量的分布,也就很难计算出期望的close form,那我们只好采用估计的方法来近似期望,例如采用样本均值来估计期望就是一种方式 (当然由于我们这里的TSP问题没有随机变量在里边自然无需期望)。
3是 Approximate cost-to-go function(value function) :动态规划的关键就在这个
上了,要想精确得到这个
需要再求解一个子优化问题,然后像剥洋葱一样层层递推到最后才能把
算出来,那么我可以通过近似未来的cost的方式来降低计算量,我只计算一个近似的cost-to-go function
。那么我们这一过程称为Approximation in value space (值空间近似)。
关于Approximation in value space 的详细介绍可参考,这里就不展开了:
王源:【强化学习与最优控制】笔记(五) 强化学习中值空间近似与策略空间近似概述我个人感觉强化学习和传统的数学优化有很多可以结合的点进去,例如Bertsekas搞的Rollout algorithm里边的Base policy 的选择就可以用很多启发式的方法。也可以采用整数规划里常用的 relaxation 或者 decomposition 的方法来近似 value function。关于Rollout算法最新的参考文献如下:http://web.mit.edu/dimitrib/www/Rollout_Constrained_Multiagent.pdf
纯粹的Learning(机器学习方法)的方法和纯粹的Search(传统数学优化解整数规划/组合优化)的方法从理论发展来看目前都快走到头了,我个人觉得未来两者之间互相结合是一个不错的道路,而强化学习这个框架恰恰可以把这两者非常有机的融合在一起。所以说传统数学优化和强化学习并不是对立的,也并不是说用强化学习就完全可以替换掉数学优化的方法了。
最后安利一下我的强化学习笔记,我也是强化学习的初学者,满打满算正式开始学习强化学习2个月还不到吧,所以如果有回答不妥的地方,希望各位轻点喷我。我个人喜欢采用笔记的形式巩固自己的学习成果,欢迎有兴趣的小伙伴可以一起参与,目前已经更新到第五期了,下面是第一期的链接:
王源:【强化学习与最优控制】笔记(一)确定性问题的动态规划我基于自动机器学习这个组合优化的子领域来回答一下这个问题吧。首先放出结论,尽管一直有人尝试通过强化学习解决AutoML问题,但是至今基于优化算法(包括贝叶斯优化、演化算法、梯度法)的AutoML算法依然保持着相对较大的优势。
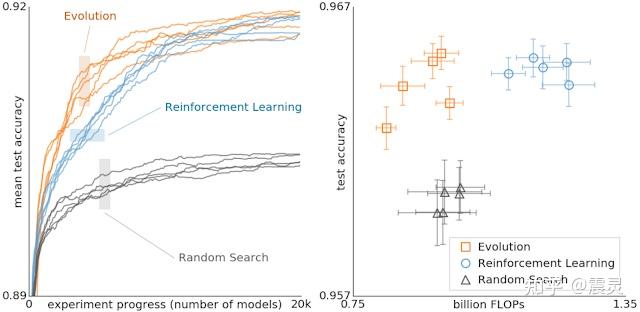
例如,在最近取得了极大关注度的神经网络架构搜索(NAS)领域,Google团队就针对强化学习和演化算法在同样搜索空间下进行了效率对比[1],从图中可以看出,演化算法的搜索效率是明显优于强化学习的。
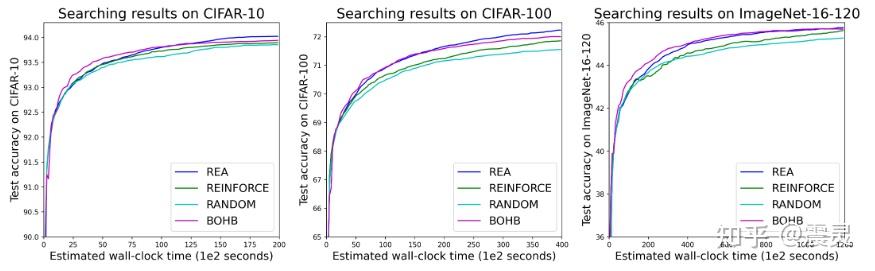
不仅仅是谷歌团队在该问题上进行了验证,悉尼科技大学的Xuanyi Dong博士也在NATS-Bench这个神经网络架构搜索Benchmark上验证了不同优化算法的搜索效率[2]。从图中可以看出演化算法(REA)相比强化学习算法(REINFORCE)具有明显优势。
此外,在NIPS 2020黑盒优化竞赛中(具体场景为AutoML参数优化,因此存在大量离散的组合优化参数),华为的HEBO框架结合了贝叶斯优化算法和多目标演化算法 NSGA-II,取得了最佳的成绩。而在该竞赛中,强化学习完全处于销声匿迹的状态。
综上所述,从学术角度来说,强化学习+组合优化这个研究方向有着巨大的研究价值,但是从工业实践的角度来说,演化算法+贝叶斯优化(代理模型)往往在实践中有着更好的效果。
参考文献
[1]. Real E, Aggarwal A, Huang Y, et al. Regularized evolution for image classifier architecture search[C]//Proceedings of the aaai conference on artificial intelligence. 2019, 33(01): 4780-4789.
[2]. Dong X, Liu L, Musial K, et al. Nats-bench: Benchmarking nas algorithms for architecture topology and size[J]. IEEE transactions on pattern analysis and machine intelligence, 2021.
大家好,俺整理了ICLR 2023关于learning to optimize (especially in solving Mixed Integer Linear Programming (MILP))的submission有好几篇,大多将度量学习(deep metric learning)、分层模型(hierarchical sequence model)和图神经网络(graph neural network)进行结合。
接下来分别详细解读一篇RL-based learning to cut的文章和一篇GNN-based end-to-end learning to solve MILP的文章。
关于这个问题的回答还可以参考:深度强化学习求解组合优化问题(路径、调度问题);DRL for OR/COR
与前面提到的End-to-end的方法不同,这篇文章是learning to cut planes (cuts)的方法,即将强化学习(Reinforcement learning)与精确算法(cutting planes)相结合。文章开篇即指出cut的选择面临三个难点及:1)应该首选哪些cuts(which cuts should be preferred);2) 应该选择多少个cuts; 3)应该怎样给所选择的cuts进行排序。
传统方法解决问题1)和2)通常依靠专家设计的hard-coded heuristics,但作者认为该方法没有考虑想VRP和排程等现实应用问题的MILP的模式。另一方面,作者认为目前learning-based方法在解决该问题方面依赖于学习一个打分函数,而忽略了学习应该选择cuts数量的重要性。对与问题3),作者认为传统方法独立的选择每一个cut, 而没有考虑cuts间的交互。因此,他们很难选择相辅相成的cuts,这可能严重阻碍解决 MILP 的效率。为解决上述3个问题,作者提出了hierarchical sequence model (HEM),作者还声称HEM是第一个同时解决该3个问题的模型。顾名思义,模型的重点在分层上,分为两层:a) 上层模型学习应该选择cuts的数量;b)下层学习选择有序子集(ordered subset,论文中作者的motivation即是所选cuts的顺序对MILP的求解效率有很大影响)的策略,子集的大小由上层模型确定。下层模型将cut选择任务建模为Sequence2Sequence学习任务,答猪认为这里回到了Pointer Network结构(关于该结构可以看这里:https://zhuanlan.zhihu.com/p/560810810)。
Cutting planes. 对于给定的MILP问题如Eqn. 1, 去掉所有整数约束得到其线性规划(linear programming, LP)松弛如Eqn. 2:
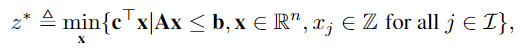
由于松弛模型扩大了可行解的集合,可以得到 ,其可以表示为下界。对于该松弛MILP的求解,MILP 求解器生成的切割被添加到连续的轮次中。 具体来说,第k轮将涉及 (i) 求解当前 LP 松弛,(ii) 生成候选cut池
,(iii) 选择子集
,(iv) 将
添加到当前 LP 松弛以获得下一个 LP 松弛,(v) 进入下一轮k+1。将所有生成的cuts添加到 LP 松弛中将最大限度地加强 LP 松弛并改善每一轮的下限。 但是,添加过多的cuts可能会导致模型过大,从而增加计算负担并呈现数值不稳定性。 因此,前人提出了cut selection来选择候选cut的适当子集,这对于提高求解 MILP 的效率具有重要意义。
Branch-and-cut. 在现代 MILP 求解器中,切平面通常与分支定界算法 结合使用,该算法被称为分支切割算法 [1](Bengio et al., 2021)。 分支定界技术通过构建搜索树来执行隐式枚举,其中每个节点代表Eqn. 1中原始问题的一个子问题。 求解过程首先选择树的叶节点并求解其 LP 松弛。令 为 LP 松弛的最优解。如果
违反原始整数约束,则通过分支创建叶节点的两个子问题(子节点)。具体来说,叶节点分别添加了约束
和
,其中
表示第 i 个变量,
表示向量
的第 i 条, 和 表示 floor 和 ceil 函数。相反,如果
是Eqn. 1的(混合)整数解,则我们获得该问题的最优解的上界,将其表示为原始界(primal bound)。在现代 MILP 求解器中,切平面的添加与分支阶段交替进行。也就是说,在分支之前在搜索树节点处添加cut以收紧它们的 LP 松弛。由于在开始分支之前加强松弛对于确保有效的树搜索具有决定性意义,因此我们只关注在根节点添加cut,这遵循[2]。
Primal-dual gap integral. 在运行分支和切割时跟踪两个重要的bounds,即全局原始边界和对偶边界 (the global primal and dual bounds),它们分别是 (1) 的最佳目标值的最优上界和下界。 通过求解器全局原始边界曲线与求解器全局对偶边界曲线之间的面积来定义原始对偶间隙积分(PD integral)。 PD integral是一种广泛用于评估求解器性能的指标。
作者首先通过一个实验来可视化其Motivation, 即cut选择的顺序很重要。Fig.1 a 和 1b 显示,以不同顺序添加相同的选定cut会导致求解器性能发生变化,这表明选定切割的顺序对于求解 MILP 很重要。

首先,给出了learning to cut问题的markov decision process, MDP定义:
State. 由于当前的 LP 松弛和生成的cut包含cut选择的核心信息,通过 ( ) 定义状态 s。 这里
表示当前 LP 松弛的数学模型,
表示候选割集的集合,
表示 LP 松弛的最优解。 为了编码状态信息,遵循[3] 。根据 (
) 的信息为每个候选剪切设计 13 个特征。 也就是说,实际上是通过一个13 维特征向量来表示状态 s。具体细节请参考原文。
Action. 考虑到所选cut的比例和顺序,通过候选切cut集合的所有有序子集定义动作空间。
Reward function. 为了评估添加cut对求解 MILP 的影响,通过 (i) 在求解 LP 松弛结束时收集的测量值(例如双界改进)来设计奖励函数,(ii) 或运行结束统计数据,例如求解时间和原始对偶间隙积分。 首先,奖励 r(s, a) 可以定义为每一步的负的对偶边界改进。 对于(ii) ,奖励 r(s, a) 可以定义为零,除了轨迹中的最后一步 (sT , aT ),即 r(sT , aT ) 由负的求解时间或负的原-对偶间隙积分(primal-dual gap integral)。
Transition function. 转移函数将当前状态 s 和动作 a 映射到下一个状态 s',其中 s' 表示通过在当前 LP 松弛处添加所选cut而生成的下一个 LP 松弛。
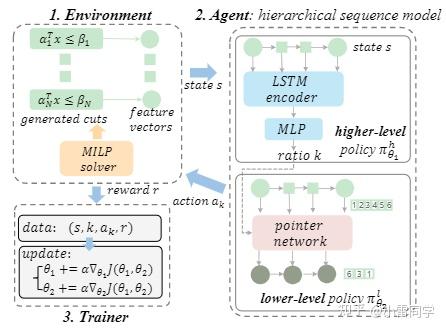
整体框架如下图Fig. 2所示,还是很简单明了,将 MILP 求解器视为为环境,将 HEM 制定为智能体进行交互,通过分层策略梯度算法训练 HEM。下面详细说一下这个HEM模型:
上下层分别学习上层policy 和下层policy
。首先,上层策略通过预测适当的比率来学习应该选择的cut的数量。 假设状态长度为N,预测比率为k,那么预测应该选择的cut数为?N?k?,其中?·?表示floor函数。 定义
:S → P([0, 1]),即一个关于action的概率分布。其次,下层策略学习选择具有由上层策略确定的具有固定大小的有序子集。 下层策略可以定义
:S ×[0, 1]→ P(A),其中
表示给定状态 s 和比率 k 的动作空间上的概率分布。 具体来说,下层策略为一个序列模型,它可以捕捉切割之间的相互作用。最后,通过概率定律推导出cut选择策略,即
。 使用神经网络细节就不谈了,比较常规,感兴趣可以看下原文。
文章采用的Policy gradient的算法训练上下层网络,分别构造了其策略梯度Loss如下:
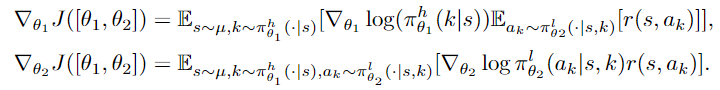
上下层共享同一个reward,上层给下层一个k类似与分层强化学习中的sub-goal。整体过程非常清晰,推荐看一下。
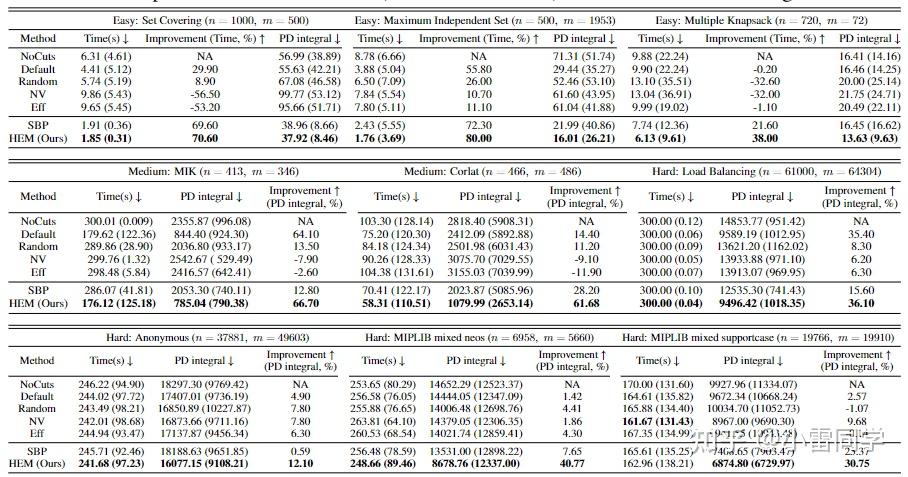
文章跟5个baseline进行了比较,总体来看效果还是不错。
与之前将ML方法结合精确算法(e.g., branch and bound)的方法求解MILP不同, 这是一篇End-to-end learning to solve MILP的方法。
作者提出了一个新的预测-搜索(predict-and-search)框架用于高效地识别高质量的可行解。在该框架中,首先预测出可行解的分布(distribution),然后基于该分布搜索最好的可行解。结果表示该框架能够在理论上和计算实验上优于固定策略。在公开的标准算例上该框架分别超过SOTA求解器SCIP和Gurobi 51%和14%。作者认为end-to-end的搜索高质量的解通常会面临两个问题:
(1)样本收集成本过高:通过监督学习的方式学习预测可行解需要大量高质量甚至最优解作为标签数据,通常学得的策略网络质量也取决于数据集的质量(解的质量及数据集大小)。但由于MILP问题本身的NP-hard性质,求得最优解是非常耗时间甚至不可能在有限时间求得的。
(2)可行性:大多数end-to-end的方法直接预测MILP的解而忽略了模型约束中的可行性要求(feasibility requirements)。因此,ML方法得到的解可能会违背模型的约束。
Motivation. 作者提出了predict-and-search框架解决上述挑战。为解决挑战(1),前人的方法是直接学习solution的分布(distribution),但仍然需要大量的solution计算。因此,作者考虑通过根据近似最优解对应的目标值来进行加权(weighing)从而近似该分布。对于挑战(2),作者实现了一个信任域(trust region),即在一个原始可行域中定义一个子域,文章中叫做以预测点为中心的球(ball centered at a prediction point)。整体框架如下图:
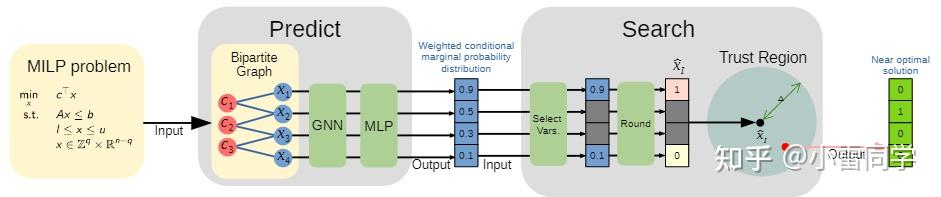
框架主要包含predict和search模块,predict模块基于GNN,其将MILP中决策变量(variable nodes)和约束(constraint nodes)当做节点nodes,不同类型节点由边edge连接并由邻接矩阵表示:

得到了MILP的graph表示就可以通过一个GNN进行embeding了,得到所有节点的高维隐变量。基于该高维隐变量,前人的方法通常是通过一个固定策略(fixing strategy)固定一个变量的子集来减小问题的大小进而学习一个条件概率分布(隐变量conditioned),但作者认为该方法将在给变量分配值时没有显示的考虑约束,会造成子问题的不可行解。因而该作者提出基于该隐变量预测所有0,1变量的加权条件边缘概率分布。
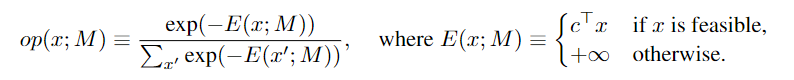
该分布由上述公式表示,M表示MILP实例x表示解,即通过一个softmax函数得到一个概率分布,其中不可行解的概率即为0,让最优解的概率最大。那么如何训练神经网络使得其预测的分布跟该分布接近呢,很容易想到类似行为克隆(Behavior cloning, BC)的方式,即采用最大似然的方式来逼近神经网络的参数,这里作者采用的是weighted log probability,即将Eqn.2 作为似然项的权重来学习:
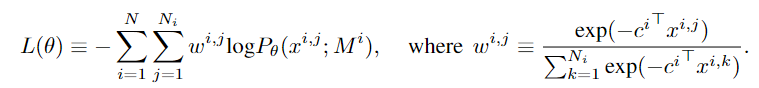
和
分别是样本实例及其可行解(label,专家轨迹)其中
表示在数据集中该实例可行解的个数。文章的总体思路就是这样,接下来介绍一下具体的weight-based sampling和trust region search过程。
a) Weight-based sampling
由于loss Eqn.3 中的高维采样(high-dimensional sampling)是无法计算的(即一个解包含d维,无法直接做sampling),为此,作者将高维分布分解为低维分分布进行降维如Eqn. 4所示, 表示solution x中的第d维,即将一个高维sampling的问题转化为一个1-维sampling的问题
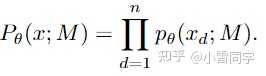
Eqn.5 计算了加权条件边际概率(一个变量对应一个概率值),因为是0,1变量所以一个变量只有两个选项要么0要么1,则 。如果在solution中第d维变量为1则
等于1,反正等于0。计算每一维变量的概率值得到一个关于所有0,1变量的概率向量
。
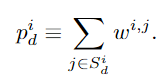
最后,Eqn. 3 的loss 函数可以改写为:
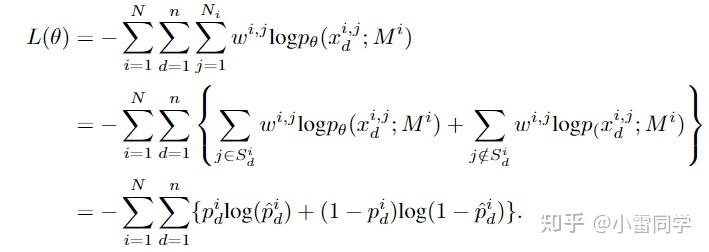
b) Search with a trust region

具体定义可以参考原文。
这篇文章同样是基于GNN求解MILP, 但该作者发现对于所有可行或不可行的MILP,GNN的处理方式都一样,这表明现有GNN缺乏表达一般MILP的能力。基于该发现,作者提出通过将MILP限制为可展开的MILP或通过添加随机特征,使得GNN能够可靠地预测最佳目标值和最佳解决方案以达到规定的精度。最后,作者在小规模的数值实验来验证了其理论发现。
文章整体偏理论,大家感兴趣可以先看一下,后续会出详细解读。三、度量学习结合(deep metric learning)
混合整数线性规划 (MILP) 求解器为其内部算法公开了大量配置参数。解决方案及其相关成本或运行时间受到配置参数选择的显着影响,即使问题实例来自同一分布。一方面,使用默认求解器配置会导致较差的次优解决方案。另一方面,为每个问题实例搜索和评估指数数量的配置是耗时的,并且在某些情况下是不可行的。基于此,该作者提出了 MILPTune — 一种基于机器学习的方法来预测 MILP 求解器的实例感知参数配置。它可以避免为每个新问题实例进行昂贵的配置参数搜索,同时针对给定实例调整求解器的行为。该方法训练基于图神经网络的度量学习模型,以将问题实例投影到具有相似成本的实例彼此更接近的空间。在推理时,给定一个新的问题实例,首先将实例嵌入到学习的度量空间中,然后使用最近邻数据预测参数配置。现实世界问题基准的经验结果表明,与基线和以前的方法相比,我们的方法预测的配置参数可将解决方案的成本提高 10-67%。
#---------------------------------------------------------------------
持续更新中,假期码字不易,可以点点赞同,yeyeyeye
俺是小雷同学,专注于强化学习理论及其在运筹优化领域的应用,对该方向感兴趣的童鞋可以关注一下俺~
以我的taste来说,这两边的结合有点不伦不类----一边追求的是精耕细作,而另外一边,我说的夸张一点,习惯的是放火烧山。
如果说我一直以来的阅读没有跑偏的话,组合优化的主流工作模式是这个样子的:先去找一个具体的问题,然后深度挖掘这个问题独有的structure,最后根据这个struture develop出针对当前问题最优且稳定的算法(以及hardness result )。
不可否认,这种case by case 的工作模式的确很大程度上是无奈之举。
最开始的时候,大家也是希望能找到一些一揽子的general result的。 可是后来np-hardness等等一系列hardness result把这一幻想击得粉碎。
于是,大家将目标转向了具体的问题,然后惊奇的发现几乎每个问题都有自己独特的flavor,从而导致了截然不同的结果。就比如说,min cut就是有polynomial 算法的,而max cut就是np-hard的。spanning tree是有polynomial算法的,但是你如果说再附加一些额外要求,比如说degree bound,就变成了np-hard的。
这样的情况在approximation algorithm里也很常见。一个问题可能原来是有不错的approximation ratio的,但是稍微twist一些条件就变成approximating to any constant ratio is np-hard了。。。
在这种情况下,去追求一个一揽子的方法着实显得有些奇怪了。
而dl群体,所追求的就是一个无比强大的可以一揽子解决一票问题的黑箱啊。
所以,我之前在阅读一些dl for combinatorial optimization的paper 的时候都忍不住要地铁老人看手机。
okay,你是说想要用dl 的方法解max cut,但是你这个方法貌似放到别的combinatorial problem上也没什么变化啊。那你是不是没有充分地利用眼前problem的structure,所以应该也是far from optimal的,对吧。
甚至,我见过最扯淡的一篇,都没有提要具体解决哪个问题。。。
读到这里,可能有的读者会问,追求generality不好吗,难道还有错么?
如果说追求generality没有别的代价的话,那当然不会有人有意见。
可是no-free-lunch theorem等一系列result告诉我们,generality always comes with costs。
越general 的方法在越具体的问题上就越可能不是最优的。而很多时候我们可能就是care少数的具体问题。
就比如说,一个ai researcher开发出了一个机械臂,非常开心,因为可以在抓100种形状上达到百分之七十五的准确率。
但问题是一个工厂很大概率不需要抓100种形状啊,而只需要处理其中的两三种。那更合适的一种处理方式是不是去专注于这两三种形状,充分理解其性质,然后努力将准确率逼近百分之百呢?
同样,我们去念phd,多才多艺肯定是好的,多知道些不同领域的东西对自己的research肯定不是坏事。
但是亚里士多德的时代早就过去了。你最后就是要专注于一个学科的一个小小分支,然后努力达到expert level。
Being versatile is good,but it is probably not sufficient to get you a phd。
反正我是这么想的。
但是人各有志,估计也有相当多的读者和我taste不一样,喜欢这类work。那也不用在我底下吵,就让我们各自美丽吧。

